Scan to PDF in Ubuntu, with Beagle Searchable Meta Data
This bash script lets you scan directly to a PDF and then search your scanned PDF's using beagle, not just by file name, but by the information (meta data), that you can save with your PDF.
I developed this script because I really want to have a paperless desk and I could not find an easy way to scan documents to PDF, (and find them again!).
A picture's worth a thousand words...
I have a "launcher" on my desktop called "scan", I just click it and....
Select colour or Grey (color or Gray) for the Americans!
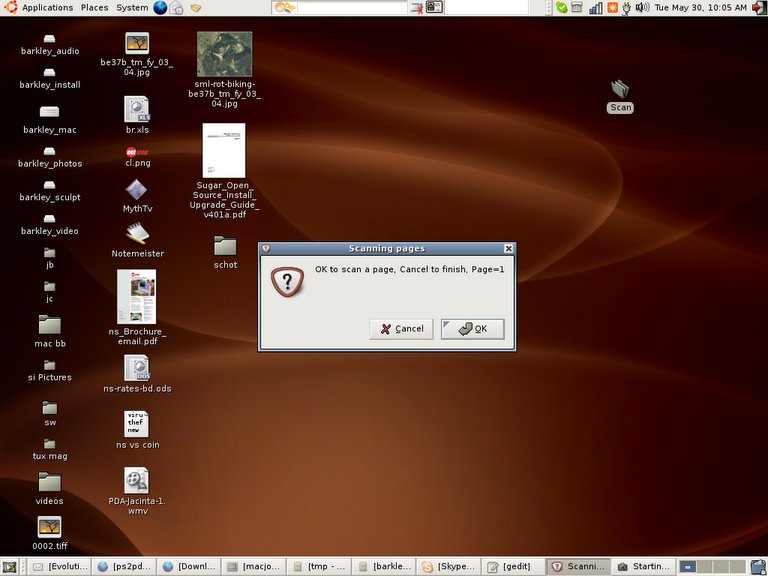
Then press OK for each page of the PDF you want to make. (Cancel to finish)
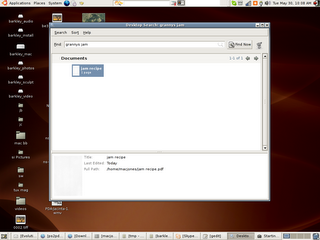
Then give the PDF a file name... (jam recipe!)
Then some meta data so beagle can find it... jam, recipe, grannys, yum.
Thats all !
Now search for "grannys jam" in Beagle.....
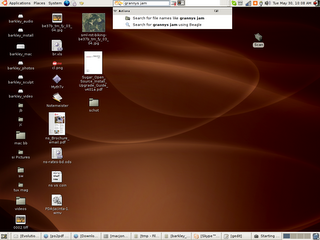
And there it is !!
Here is the script, it was made pretty fast so......
Please feel free to mess about with it. And post improvements back here !
Programs you'll need..
zenity
ps2pdf
pdftk
scanimage
Copy the script into its own directory, chmod u+rxw. Thats all!.
-----------------------------------
#!/bin/sh
#scan to pdf with metadata, by Mac Jones, New Zealand
#http://maconstuff.blogspot.com/
#scan a batch
#decide grey or colour (gray or color for the Americans!)
colour=`zenity --list --title "Color or Gray?" --radiolist --column "-" --column "Scan" TRUE Gray FALSE Color`
a=0 #page counter
cont=1 #should we continue?
until [ $cont -eq "0" ] #keep doing it until cont variable is not a zero.
do
echo -n "$a "
let "a+=1"
if zenity --question --text "OK to scan a page, Cancel to finish, Page=$a" --title "Scanning pages"
then
cont=1
scanimage --format pnm --resolution 150 --mode $colour > "$a.pnm"
else
cont=0
fi
done # No surprises, so far.
#convert the raw file to postscript
convert -density 150 *.pnm out.ps | zenity --progress --auto-close --title "Converting to Postscript"
#convert the postscript to pdf
ps2pdf out.ps out.pdf | zenity --progress --auto-close --title "Converting Postscript to PDF"
#remove raw scan files
rm *.pnm
#remove old ps files
rm out.ps
#beep to get attention after processing
echo -e "\a"
#add the metadata and file name.
#this meta data can be searched from Beagle in Ubuntu.
#echo "Please enter a name for the PDF file (** no .pdf on end)"
nm=`zenity --entry --text "Enter file name, (no .pdf on the end)" --title "File Name?"`
#echo "Please enter Metadata for searching"
meta=`zenity --entry --text "Meta data for searching" --entry-text=$nm --title "Meta Data for Searching"`
echo "InfoKey: Producer" > tmp
echo "InfoValue: $meta" >> tmp
echo "InfoKey: Keywords" >> tmp
echo "InfoValue: $meta" >> tmp
echo "InfoKey: Title" >> tmp
echo "InfoValue: $nm" >> tmp
#update the metadata
pdftk out.pdf update_info tmp output "$nm.pdf"
#rm metadata file and pdf
rm tmp
rm out.pdf
zenity --info --text="All done, $nm.pdf is ready!" --title "Thanks!"
--------------------
I developed this script because I really want to have a paperless desk and I could not find an easy way to scan documents to PDF, (and find them again!).
A picture's worth a thousand words...
I have a "launcher" on my desktop called "scan", I just click it and....
Select colour or Grey (color or Gray) for the Americans!

Then press OK for each page of the PDF you want to make. (Cancel to finish)
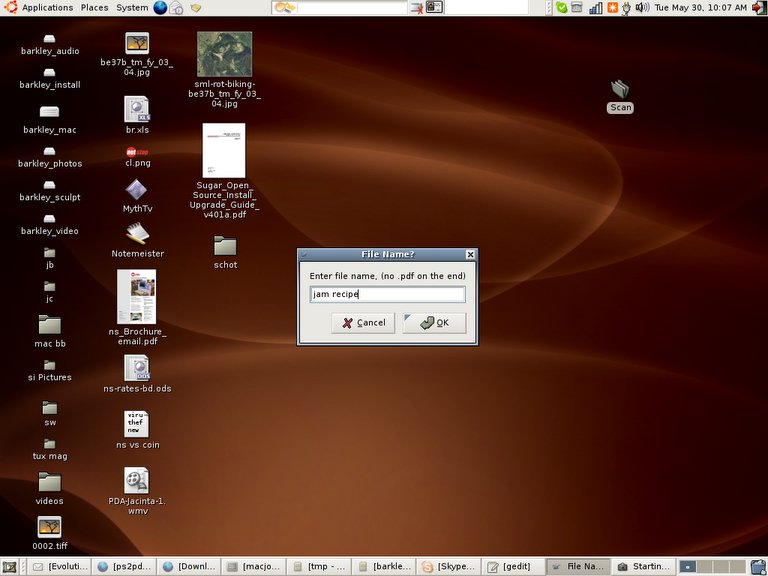
Then give the PDF a file name... (jam recipe!)
Then some meta data so beagle can find it... jam, recipe, grannys, yum.

Thats all !
Now search for "grannys jam" in Beagle.....
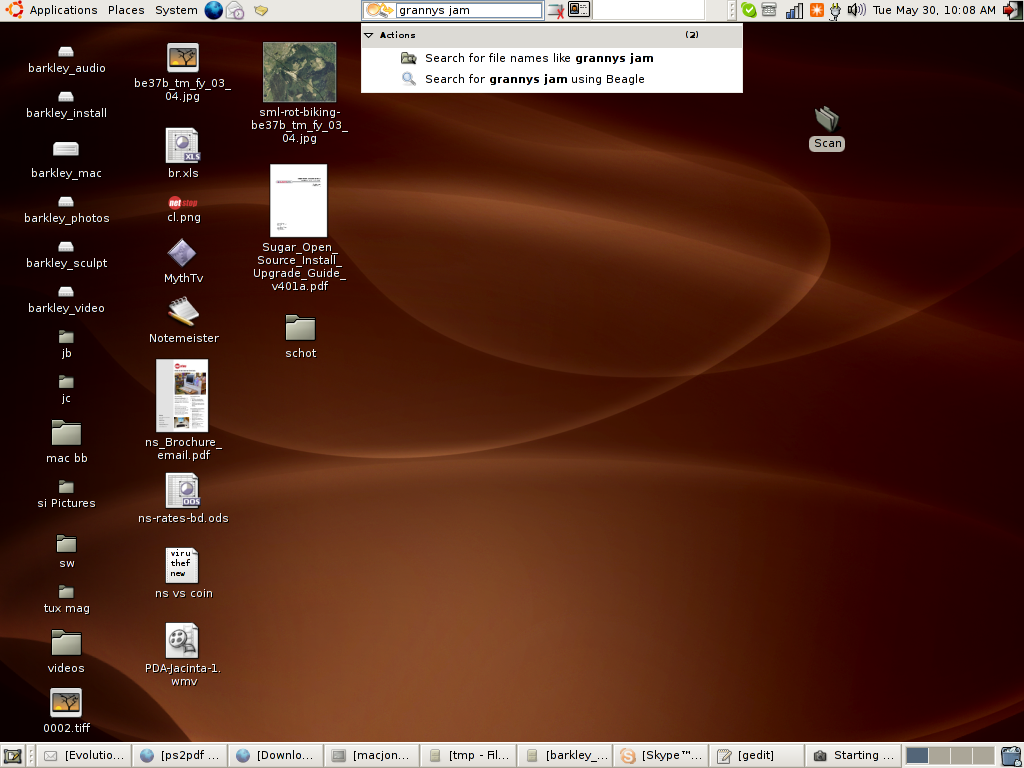
And there it is !!

Here is the script, it was made pretty fast so......
Please feel free to mess about with it. And post improvements back here !
Programs you'll need..
zenity
ps2pdf
pdftk
scanimage
Copy the script into its own directory, chmod u+rxw. Thats all!.
-----------------------------------
#!/bin/sh
#scan to pdf with metadata, by Mac Jones, New Zealand
#http://maconstuff.blogspot.com/
#scan a batch
#decide grey or colour (gray or color for the Americans!)
colour=`zenity --list --title "Color or Gray?" --radiolist --column "-" --column "Scan" TRUE Gray FALSE Color`
a=0 #page counter
cont=1 #should we continue?
until [ $cont -eq "0" ] #keep doing it until cont variable is not a zero.
do
echo -n "$a "
let "a+=1"
if zenity --question --text "OK to scan a page, Cancel to finish, Page=$a" --title "Scanning pages"
then
cont=1
scanimage --format pnm --resolution 150 --mode $colour > "$a.pnm"
else
cont=0
fi
done # No surprises, so far.
#convert the raw file to postscript
convert -density 150 *.pnm out.ps | zenity --progress --auto-close --title "Converting to Postscript"
#convert the postscript to pdf
ps2pdf out.ps out.pdf | zenity --progress --auto-close --title "Converting Postscript to PDF"
#remove raw scan files
rm *.pnm
#remove old ps files
rm out.ps
#beep to get attention after processing
echo -e "\a"
#add the metadata and file name.
#this meta data can be searched from Beagle in Ubuntu.
#echo "Please enter a name for the PDF file (** no .pdf on end)"
nm=`zenity --entry --text "Enter file name, (no .pdf on the end)" --title "File Name?"`
#echo "Please enter Metadata for searching"
meta=`zenity --entry --text "Meta data for searching" --entry-text=$nm --title "Meta Data for Searching"`
echo "InfoKey: Producer" > tmp
echo "InfoValue: $meta" >> tmp
echo "InfoKey: Keywords" >> tmp
echo "InfoValue: $meta" >> tmp
echo "InfoKey: Title" >> tmp
echo "InfoValue: $nm" >> tmp
#update the metadata
pdftk out.pdf update_info tmp output "$nm.pdf"
#rm metadata file and pdf
rm tmp
rm out.pdf
zenity --info --text="All done, $nm.pdf is ready!" --title "Thanks!"
--------------------
posted by Mac at 10:20 am
![]()

5 Comments:
Now I have to find a driver for my Epson scanner. Thanks,
This comment has been removed by a blog administrator.
When I use the script everything seems to work, but I end up with a blank .pdf document. Could someone help since I'd really like to use this process. I'm using an HP PSC 1350 All-in-One scanner. Thanks.
Try gscan2pdf here:
https://sourceforge.net/project/showfiles.php?group_id=174140
Lets you preview your scan before you produce the PDF, reorder pages, all in a nice GTK-based GUI.
Jeff
Thanks for the GREAT script (including jason's mods).
I've modified the script further to scan to tif and to have tesseract do an ocr pass on the image. After a verification window, this text is then saved as keyword metadata.
The system works so well that I ordered a document scanner to get rid of all my office clutter.
Through all this, I noticed that beagle doesn't actually index the keyword metadata... so I'm wondering how the original demo worked. I submitted a patch to index pdf keywords here, and apparently it got accepted. Hopefully it'll make it in 0.2.18...
http://bugzilla.gnome.org/show_bug.cgi?id=463003
I've got the patch available (for 0.2.13 and 0.2.16... the filter api changed somewhere in there) in case anyone wants it...
Post a Comment
<< Home